逻辑斯谛回归与最大熵模型
逻辑斯谛回归(logistic regression)是统计学习中的经典分类方法。最大熵是概率模型学习的一个准则,将其推广到分类问题得到最大熵模型(maximum entropy model)。两者都属于对数线性模型。
逻辑斯谛回归模型
逻辑斯谛分布
首先介绍逻辑斯谛分布(logistic distribution, LR)。
设
是连续随机变量, 服从逻辑斯谛分布是指 具有下列分布函数和密度函数: 式中, 为位置参数, 为形状参数。
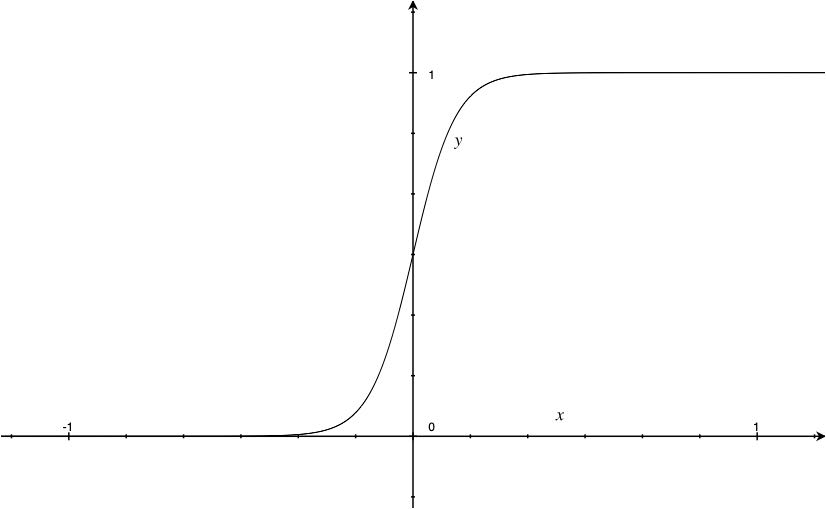 上图为函数
上图为函数
如果事件发生的概率是
Sigmoid函数满足以下形式
该函数单调递增,值域在 之间,LR为什么使用Sigmoid函数的形式?
回答: 若考虑单变量/特征,LR的假设为特征服从均值不同但方差相等的高斯分布,也就是
模型参数估计
给定训练集
多项逻辑斯谛回归
假设离散随机变量取值为
最大熵模型
最大熵模型由最大熵原理推到实现。